Définition de Disallow:

Définition de Disallow: :
 Disallow: est une directive utilisée dans les fichiers robots.txt qui permet de demander aux robots des moteurs de recherche de ne pas explorer une page ou le répertoire complet d’un site web.
Disallow: est une directive utilisée dans les fichiers robots.txt qui permet de demander aux robots des moteurs de recherche de ne pas explorer une page ou le répertoire complet d’un site web.
Le fichier robots.txt permet d’indiquer aux robots des moteurs de recherche un certain nombre de directives sur leur comportement lorsqu’ils crawlent un site web. Si vous ne voulez pas que ces robots explorent une partie de votre site, la directive Disallow: s’impose…
La directive Disallow: permet, dans un fichier robots.txt, d’indiquer aux robots comme Googlebot ou Bingbot ce qu’ils doivent faire lors de leur exploration, et plus précisément les zones de votre site où ils ne doivent pas aller.
La syntaxe de cette directive est la suivante :
Disallow: [path]
Où [path] indique le début (ou une règle) de l’URL des pages à ne pas crawler.
Et en voici quelques exemples d’utilisation (pour un site de type https://www.exemple.com/) :
Disallow:
Aucune restriction. Accès libre.
Disallow: /
Le site est entièrement interdit à l’exploration.
Disallow: blog
Aucune page dont l’URL commence par « blog » ne sera explorée (exemple : https://www.exemple.com/blog ou https://www.exemple.com/blog/exemple.php).
Disallow: /*.pdf
Aucun document dont l’URL contient « .pdf » ne sera exploré (exemple : https://www.exemple.com/contrat.pdf ou https://www.exemple.com/blog/document.pdf ou https://www.exemple.com/blog/document.pdf?langue=fr).
Disallow: /*.pdf$
Aucun document dont l’URL se termine par « .pdf » ne sera exploré (exemple : https://www.exemple.com/contrat.pdf ou https://www.exemple.com/blog/document.pdf).
Etc.
Notez bien que la directive « Disallow: » n’interdit pas l’indexation de l’existence de l’URL par Google. Dans ce cas, un message apparaîtra dans la SERP, expliquant ce fait avec le message « Aucune information n’est disponible pour cette page » accompagné d’un lien vers une page d’explication :
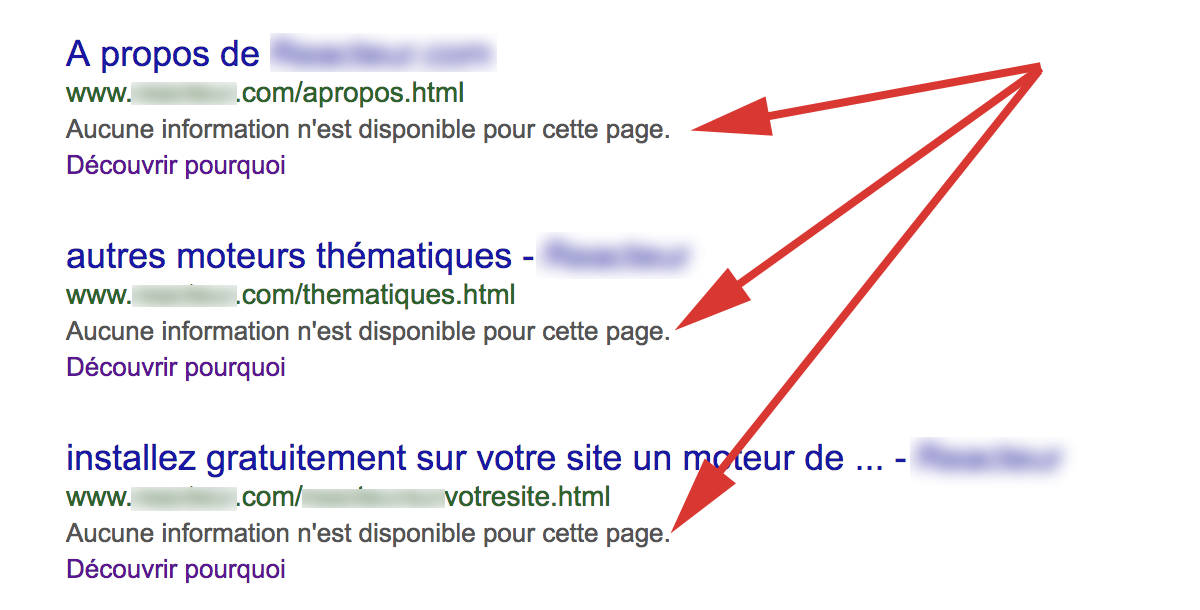 Message dans la SERP Google lorsqu’une URL est indexée mais interdite au crawl par une directive Disallow: dans le fichier robots.txt. |
En cela, la directive Disallow: est donc différente et complémentaire de la balise meta robots « noindex » (qui, pour sa part, interdit plus clairement l’indexation).
Voici également quelques liens pour aller plus loin sur le sujet :
- Robots.txt : Disallow all / Bloquer tous les robots
- Caractéristiques du fichier robots.txt (Google)
- Différences entre disallow, noindex et nofollow (WebRankInfo)
- Google a modifié son mode de lecture des fichiers robots.txt (Abondance)
Et 2 vidéos de Matt Cutts et Abondance qui vous en disent un peu plus sur la façon dont fonctionnent les robots des moteurs, la balise meta robots et le noindex :
Spiders, Robots, Crawlers : comment ça marche ? (Abondance)
When would someone use « noindex, follow » in a robots meta tag? (Google, Matt Cutts)
Laisser un commentaire