Définition du TF*IDF

Définition du TF*IDF :
 Le TF*IDF (pour Term Frequency * Inverse Document Frequency) est le résultat d’un calcul, dans l’algorithmie des moteurs de recherche, permettant d’obtenir un poids, une évaluation de la pertinence d’un document par rapport à un terme, en tenant compte de deux facteurs : la fréquence de ce mot dans le document (TF) et le nombre de documents contenant ce mot (IDF) dans le corpus étudié.
Le TF*IDF (pour Term Frequency * Inverse Document Frequency) est le résultat d’un calcul, dans l’algorithmie des moteurs de recherche, permettant d’obtenir un poids, une évaluation de la pertinence d’un document par rapport à un terme, en tenant compte de deux facteurs : la fréquence de ce mot dans le document (TF) et le nombre de documents contenant ce mot (IDF) dans le corpus étudié.
L’algorithmie des moteurs de recherche a généré depuis des décennies bon nombre de formules mathématiques et de concepts servant à mesurer la pertinence d’une page web par rapport à une requête donnée. Parmi celles-ci, la notion de TF*IDF est certainement la plus connue et se trouve peut-être encore au coeur des algorithmes des moteurs actuels…
Les tous premiers moteurs de recherche (Infoseek, Webcrawler, Lycos, Excite, etc. jusqu’à Altavista) prenaient majoritairement en compte comme critère de pertinence le nombre de fois où un terme (la requête demandée) était présent dans la page web analysée. On parle alors de Term Frequency (TF), idée proche de l’obsolète (aujourd’hui) « densité de mots clés ». La taille du Web augmentant, ce critère s’est rapidement avéré insuffisant. Un deuxième niveau d’analyse a donc été introduit à ce moment-là avec la notion d’IDF (Inverse Document Frequency), concept introduit par une chercheuse anglaise, Karen Spärck Jones, dès 1972. Ce critère mesure le nombre de documents dans le corpus étudié qui contiennent un terme donné, rapporté à l’ensemble des documents analysés.
Gerard Salton, figure emblématique et incontournable de l’algorithmie des moteurs de recherche et du célèbre modèle vectoriel, proposera par la suite une nouvelle étape avec, en 1975, l’avénement du TF*IDF (Term Frequency * Inverse Document Frequency) qui donne pour un terme donné, trouvé dans un document donné, un « poids » qui indique si le document est particulièrement intéressant à renvoyer pour une requête sur ce terme. Voici la formule originelle du TF*IDF (pour les fanas de mathématiques) :
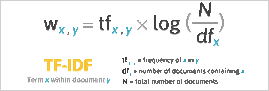 La formule originelle du TF*IDF… Source de l’image : DR |
Au fil des années, la formule de poids TF*IDF a été perfectionnée, de nombreuses variantes ont alors été inventées et testées. Plus récemment, l’une de celles qui a fourni les meilleurs résultats dans un moteur de recherche est connue sous le nom « Okapi BM25 » dont voici la formule :
 La formule d’Okapi BM25, variante plus récente du TF*IDF… Source de l’image : DR |
D’une façon générale, le calcul du TF*IDF permet de donner un poids à un document par rapport à un terme, en tenant compte à la fois de la fréquence de ce mot dans la page mais également de sa rareté relative sur le Web. Il est à noter que certains auteurs parlent plutôt de WDF*IDF (Within Document Frequency * Inverse Document Frequency) pour désigner ce poids. Le concept de TF*IDF, sous une forme ou sous une autre, est certainement encore aujourd’hui pris en compte par de nombreux moteurs, sans qu’aucune information officielle à ce sujet ne soit cependant dévoilée par Google et consorts. Prudence donc…
Vous trouverez plus d’informations détaillées sur le TF*IDF est ses principaux dérivés dans deux articles rédigés par Philippe Yonnet, dans notre lettre professionnelle « Recherche et Référencement » : Le cosinus de Salton : un classique (méconnu) des moteurs de recherche et WDF*IDF : la ‘formule magique’ des référenceurs allemands. Plus, bien sûr, les 7 articles sur le fonctionnement des moteurs de recherche, rédigés de main de maître par Sylvain Peyronnet et consorts, toujours dans notre lettre professionnelle. De saines lectures qui nous permettent de « soulever le capot » des moteurs de recherche…
Laisser un commentaire